币界网报道:
人工智能艺术领域正变得越来越热。Sana是Nvidia推出的一种新的人工智能模型,它在消费级硬件上运行高质量的4K图像生成,这要归功于与传统图像生成器工作方式略有不同的技术的巧妙组合。
Sana的速度来自Nvidia所谓的“深度压缩自动编码器”,它将图像数据压缩到原始大小的1/32,同时保持所有细节的完整性。该模型将其与Gemma 2 LLM相结合,以理解提示,创建了一个在适度硬件上远远超出其重量等级的系统。
如果最终产品与公开演示,Sana承诺成为一款全新的图像生成器,可在要求较低的系统上运行,这对Nvidia来说将是一个巨大的优势,因为它试图接触到更多的用户。
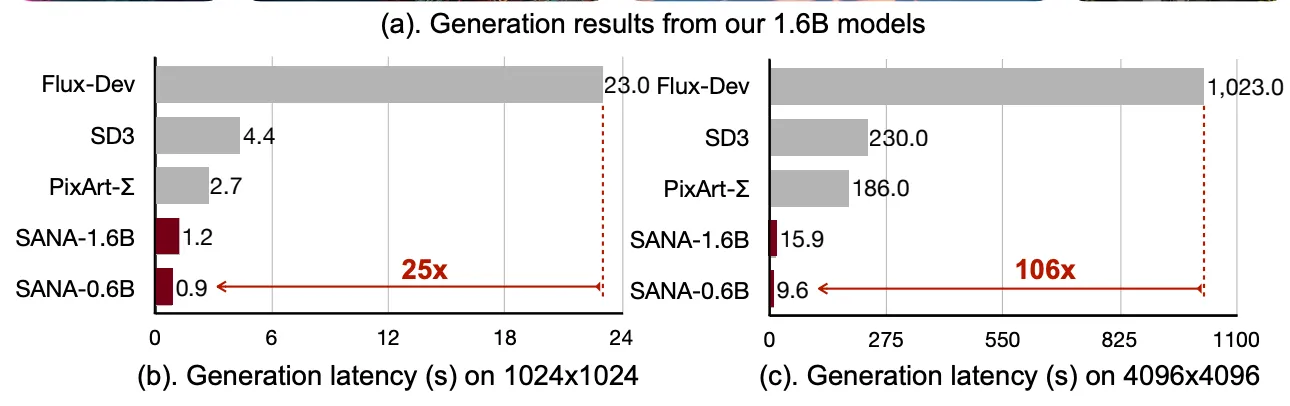
Nvidia的团队写道:“Sana-0.6B与现代巨型扩散模型(如通量-12B)相比非常有竞争力,其测量吞吐量小20倍,快100倍以上。”Sana的研究论文“此外,Sana-0.6B可以部署在16GB笔记本电脑GPU上,生成1024×1024分辨率的图像只需不到1秒的时间。”
 图片:Nvidia
图片:Nvidia
是的,你没看错:Sana是一个6亿参数的模型,它与20倍于其大小的模型竞争,同时在很短的时间内生成4倍大的图像。如果这听起来好得令人难以置信,你可以在一个特殊的界面上自己尝试一下由麻省理工学院设立.
Nvidia的时机再恰当不过了,最近推出的型号稳定扩散3.5,爱人Flux,以及新Auraflow已经在争夺注意力了。英伟达计划很快以开源形式发布其代码,此举可能会巩固其在人工智能艺术界的地位,同时促进其GPU和软件工具的销售。
圣三一使萨娜如此优秀
Sana基本上是对传统图像生成器工作方式的重新想象。但有三个关键因素使这个模型如此高效。
首先,是萨娜的深度压缩自动编码器,这将图像数据缩小到其原始大小的3%。研究人员表示,这种压缩使用了一种专门的技术,可以保持复杂的细节,同时大大降低所需的处理能力。
您可以将其视为Flux或Stable Diffusion中实现的可变自动编码器的优化替代品。Sana的编码/解码过程更快、更高效。
这些自动编码器基本上将潜在的表示(人工智能理解和生成的)转换为图像。
其次,Nvidia彻底改变了其模型处理提示的方式——通过编码和解码文本。大多数人工智能艺术工具使用T5或CLIP等文本编码器,基本上将用户的提示翻译成人工智能可以理解的东西——文本的潜在表示。但Nvidia选择使用谷歌的Gemma 2 LLM。
这个模型基本上做了同样的事情,但仍然很轻,同时仍然能捕捉到用户提示中的细微差别。输入“薄雾笼罩的山脉上有古老遗迹的日落”,它就会得到图片——字面意思——而不会耗尽你电脑的内存。
但线性扩散变换器可能是与传统模型的主要区别。虽然其他人工智能工具使用复杂的数学运算来阻碍处理,但Sana的LDT消除了不必要的计算。结果如何?闪电般快速的图像生成,没有质量损失。把它想象成在迷宫中找到一条捷径——同样的目的地,但更快的路线。
这可能是人工智能艺术家从Flux或Stable Diffusion等模型中了解的UNet架构的替代方案。UNet是通过应用噪声去除技术将噪声(没有意义的东西)转化为清晰的图像,通过几个步骤逐步细化图像——这是图像生成器中最耗费资源的过程。
因此,萨那的LDT基本上执行了与稳定扩散中的UNet相同的“去噪”和转换任务,但采用了更精简的方法。这使得LDT成为Sana图像生成中实现高效率和高速的关键因素,而UNet仍然是Stable Diffusion功能的核心,尽管计算要求更高。
基本测试
由于该模型尚未公开发布,我们不会分享详细的评论。但我们从模型的演示网站上获得的一些结果相当不错。
事实证明,萨娜跑得很快。相比之下,它能够生成4K图像,在不到10秒内渲染30步。这甚至比Flux Schnell在4个步骤中生成1080p大小的类似图像所需的时间还要快。
以下是一些结果,使用与我们用于基准测试其他图像生成器相同的提示:
提示1:“一只巨大的蜘蛛在丛林中追逐一个女人的手绘插图,极其可怕、痛苦、黑暗和令人毛骨悚然的风景,恐怖,模拟摄影影响的暗示,素描。”
提示2:一张黑白照片,一位留着长直发的女性,穿着全黑的衣服,突出了她的曲线,坐在现代沙发前的地板上。她自信地对着镜头摆姿势,蹲下时展示了她修长的双腿。背景采用极简主义设计,在浅灰色墙壁和深色服装的鲜明对比下,突显了她的优雅姿态。她的表情流露出自信和老练。彼得·林德伯格使用哈苏X2D 105mm镜头以f/4光圈设置拍摄。ISO 63。专业的色彩分级增强了视觉吸引力。
提示3:穿着西装的蜥蜴
提示4:一个美丽的女人躺在草地上
提示5:“一只狗站在电视上,屏幕上显示着‘解密’这个词。左边是一个穿着西装的女人,手里拿着一枚硬币,右边是一个机器人站在急救箱上。整体风景超现实。”
该模型也未经审查,对男性和女性的解剖结构都有正确的理解。一旦发布,它也将更容易进行微调。但考虑到架构变化的重要性,模型开发人员理解其复杂性并发布Sana的自定义版本将面临多大的挑战还有待观察。
基于这些早期结果,仍在预览中的基础模型似乎很适合现实主义,同时对其他类型的艺术也足够通用。它在空间意识方面很好,但其主要缺陷是缺乏适当的文本生成,在某些情况下缺乏细节。
速度声明非常令人印象深刻,考虑到目前只有通过升级技术才能正确实现这种尺寸,生成4096x4096的能力——在技术上高于4k——是一件了不起的事情。
它将是开源的事实也是一个主要的积极因素,因此我们可能很快就会审查能够生成超高清图像而不会给消费硬件带来太大压力的模型和微调。
Sana的体重将在项目的官方Github.



.png) 165
165



.png)
















