币界网报道:
Meta刚刚推出了一种新的人工智能训练方法,可以改善机器处理信息和响应查询的方式。配音思维偏好优化(TPO),这种技术教语言模型在吐出答案之前进行内部审议。换句话说:他们在思考,有点。
TPO基本上就像给人工智能一个心理暂停按钮,让它仔细考虑事情,而不是脱口而出想到的第一个反应。结果如何?更尖锐、更微妙的回答,听起来不像机器人,更像一个有思想的人。
这意味着,TPO可以使Meta更接近于为OpenAI等专有模型提供开源替代品草莓(又名o1),以其复杂的问题解决能力而闻名。
Meta的方法不同于“思维链”提示等传统方法,后者迫使人工智能通过不同的迭代来展示其工作。TPO将心理体操保密,让模特在一次拍摄中独立完成所有事情。
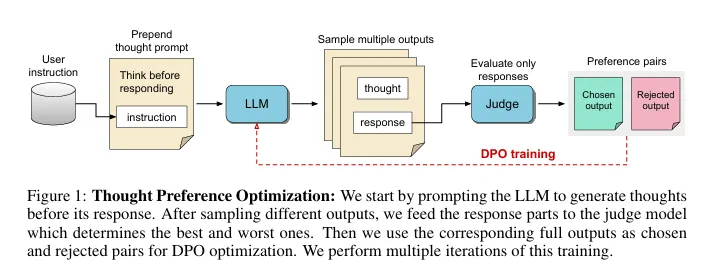
训练过程也不同于简单地告诉模型“一步一步地思考”。研究人员从一个基本的指令遵循模型开始,在回答之前提示它生成内部想法。通过迭代强化学习,人工智能在一个只评估最终输出的判断模型的指导下磨练了它的思维技能,即用户所看到的。
 图片:Meta
图片:Meta
这种不干涉的方法使人工智能能够发展出自己独特的思维模式,从而有可能带来更具创造性和适应性的问题解决。这是朝着人工智能迈出的一步,它不仅遵循规则,而且真正理解规则背后的推理。
Meta的创新灵感来自认知科学,模仿了人类在解决复杂问题之前暂停和反思的倾向。如果人工智能模型学会将更多的“计算时间”用于更艰巨的任务,那么下一代开源模型可能会大大优于我们目前使用的模型。
最棒的是,Meta的TPO技术不需要堆积如山的新数据来发挥其魔力。它建立在现有的人工智能架构之上,对其进行调整,以模拟一个没有人类牵手的思维过程。这可以快速跟踪更智能的人工智能助手、聊天机器人和其他基于语言的工具的发展,让他们在解决问题的方法上更有创造力。
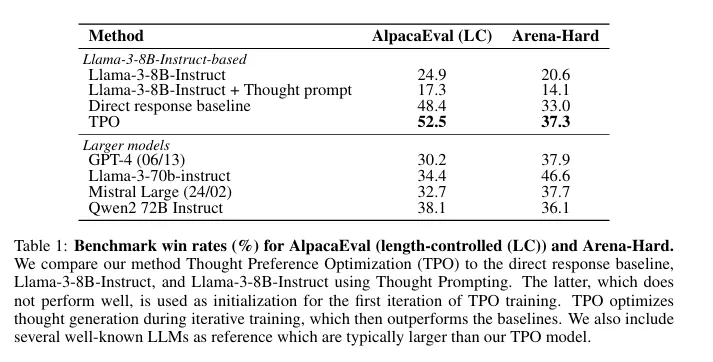
Meta的研究人员根据行业标准基准测试了他们的方法。TPO训练的模型展示了他们新发现的认知肌肉,在复杂任务上表现优于非思考的模型。
 图片:Meta
图片:Meta
更接近开源草莓?
Meta在使人工智能更加智能的领域取得了有趣的进展。就在三个月前,其研究人员介绍了“系统2蒸馏,“一种教大型语言模型(LLM)如何解决复杂任务而不输出不必要步骤的技术。
系统2蒸馏受人类认知过程的启发,教会LLM在不需要逐步提示的情况下执行复杂任务,这通常被认为是高级提示工程中的首选方法。通过微调对系统2提示技术的验证响应模型,研究人员表明,人工智能可以内化复杂的推理技能,通常与显式推理方法的性能相匹配或超越。
系统1思维快速、直观、自动化。这是我们用于快速判断、模式识别和熟悉任务的心理过程。从人工智能的角度来看,这与大型语言模型通常的操作方式相一致——基于学习到的模式快速生成响应。
相比之下,系统2思维是缓慢、深思熟虑和分析性的。这是人类为复杂的问题解决、逻辑推理和规划而进行的处理类型。人工智能研究人员一直在努力通过各种提示技术在语言模型中复制这一点,这些技术迫使人工智能逐步显示其工作或推理。
Meta的思维偏好优化和对系统2蒸馏的相关研究代表了在人工智能中弥合这两种思维模式的尝试。目标是在不牺牲系统1处理的速度和效率的情况下,使人工智能模型能够进行深入的系统2式推理。
这种方法涉及训练人工智能将复杂的推理过程内化。通过这样做,这些模型可以更有效地解决复杂的问题,模仿人类在获得任务专业知识时如何从有意识、费力的思维过渡到更自动化的处理。
时机再好不过了,因为Meta的研究是在开源人工智能领域动荡的一个月之后进行的。大肆宣传反射70B这个被吹捧为推理引擎的模型,结果却成了烟雾和镜子。OpenAI发布o1之前承诺的具有嵌入式思想链的模型最终无法兑现其承诺,一些用户甚至指责创建者只是在Anthropic的Claude上使用了包装器。
现在,它的开发人员指指点点在彼此不同公共验尸,让人工智能社区摇摇欲坠。这个想法背后的人马特·舒默目前正在用自己的硬件和数据集训练一个新版本。
如果Meta的方法被证明是成功的,那么它可能会为开源竞争对手铺平道路OpenAI的o1模型开源替代方案可以使这种先进的人工智能思维的获取民主化。
编辑人安德鲁·海沃德



.png) 298
298



.png)















