币界网报道:
一项新技术可以让人工智能模型严格控制能量摄入,从而可能减少电力消耗在不影响质量的情况下,高达95%。
BitEnergy AI,股份有限公司的研究人员开发了线性复杂性乘法(L-Mul),一种在人工智能计算中用更简单的整数加法代替能量密集型浮点乘法的方法。
对于那些不熟悉这个术语的人来说,浮点是一种数学简写,它允许计算机通过调整小数点的位置来有效地处理非常大和非常小的数字。你可以把它想象成二进制的科学符号。它们对于人工智能模型中的许多计算至关重要,但它们需要大量的能量和计算能力。数字越大,模型越好,需要的计算能力也就越强。Fp32通常是一个全精度模型,开发人员将精度降低到fp16、fp8甚至fp4,这样他们的模型就可以在本地硬件上运行。
 图片:维基百科
图片:维基百科
AI贪婪的食欲因为电力已经成为人们日益关注的问题。仅ChatGPT每天就消耗564 MWh—足以供电18000个美国家庭。预计整个人工智能行业将消费到2027年,每年85-134太瓦时,与比特币挖矿操作大致相同,根据剑桥另类金融中心.
L-Mul通过重新构想人工智能模型处理计算的方式,正面解决了人工智能的能源问题。L-Mul使用整数加法来近似这些运算,而不是复杂的浮点乘法。因此,例如,L-Mul不是将123.45乘以67.89,而是使用加法将其分解为更小、更容易的步骤。这使得计算速度更快,能耗更低,同时仍保持准确性。
结果似乎很有希望。研究人员声称:“在张量处理硬件中应用L-Mul运算可以通过逐元素浮点张量乘法降低95%的能量成本,并降低80%的点积能量成本。”。没有变得过于复杂,这意味着很简单:我根据这项研究,如果模型使用这种技术,思考所需的能量将减少95%,提出新想法所需的精力将减少80%。
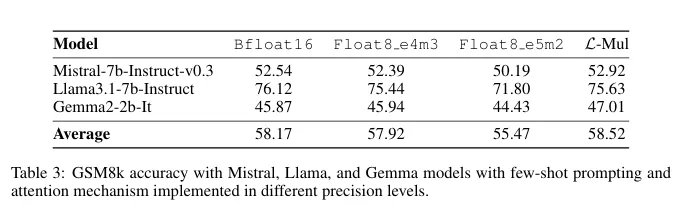
该算法的影响不仅限于节能。在某些情况下,L-Mul的性能优于当前的8位标准,在使用更少的位级计算的同时实现了更高的精度。对自然语言处理、视觉任务和符号推理的测试显示,平均性能下降了0.07%—对于潜在的节能来说,这是一个可以忽略不计的权衡。
基于Transformer的模型是GPT等大型语言模型的支柱,可以从L-Mul中受益匪浅。该算法无缝集成到注意力机制中,这是这些模型中计算密集型的一部分。对Llama、Mistral和Gemma等流行模型的测试甚至显示,在某些视觉任务中,准确性有所提高。
 图片:Bitenergy.ai通过ArXiv
图片:Bitenergy.ai通过ArXiv
在运营层面,L-Mul的优势变得更加明显。研究表明,将两个float8数字相乘(就像今天的人工智能模型一样)需要325次运算,而L-Mul只需要157次,不到一半。该研究总结道:“总结一下误差和复杂性分析,L-Mul比fp8乘法更有效、更准确。”。
但没有什么是完美的,这种技术有一个主要的弱点:它需要一种特殊类型的硬件,因此目前的硬件没有得到优化以充分利用它。
原生支持L-Mul计算的专用硬件计划可能已经在进行中。研究人员说:“为了释放我们提出的方法的全部潜力,我们将在硬件级别实现L-Mul和L-Matmul内核算法,并为高级模型设计开发编程API。”。这可能会导致新一代快速、准确、超便宜的人工智能模型,使节能人工智能成为现实。



.png) 223
223



.png)